
長野県の山岳事故データを活用した予測手法を構築
本研究の要点
- 深層学習による言語モデルBERTを活用して、登山計画段階の情報から、4つの主要遭難事故リスク(滑落・転倒・疲労・道迷い)を予測する手法を開発。
- 長野県の過去10年間の山岳事故データを用いてモデルの検証を行い、転落、道迷いについて適合率、再現率ともに60%以上を達成。
- 将来的には、登山用のモバイルアプリやサービスへの応用により、登山者や管理者が事前にリスクを把握し、適切な装備・登山計画で遭難事故の防止への貢献が期待。
研究の概要
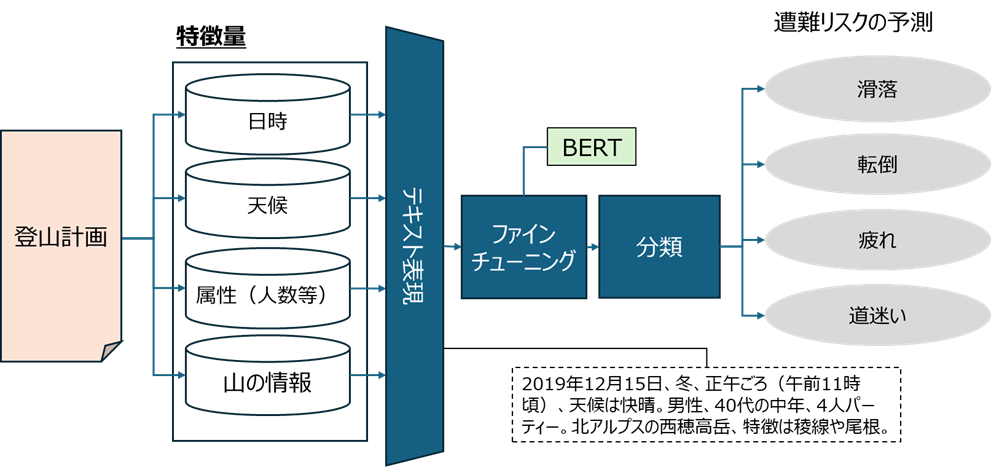
上智大学大学院 応用データサイエンス学位プログラムの佐藤 多恵子氏と深澤 佑介准教授は、登山計画段階で得られる情報(登山日、登山ルート、気象条件、人数、登山者の年代など)を深層学習による言語モデル(BERT, *1)に入力し、それらの文脈情報をもとに登山の事故リスクを予測する手法を開発しました。本研究を活用することで、登山者は事前に事故リスクを把握できるようになり、適切な装備選択や計画変更でより安全に登山を行うことができます。
山岳遭難事故は登山人口の増加とともに深刻な社会問題となっており、従来の統計的手法による事故分析では事前の個別のリスク予測が困難でした。特に登山計画段階で利用可能な情報を活用した予測手法は十分に検討されておらず、登山者は適切な準備や装備選択の判断材料を得ることが困難な状況でした。そこで本研究では、AI技術を活用して登山前の情報から、BERTによる「滑落」、「転倒」、「疲労」、「道迷い」の4つの主要遭難事故リスクを予測する手法の開発を目指しました。
長野県における2014年から2023年の山岳事故データ2596件を用いて、BERTによる遭難事故予測モデルを学習および検証した結果、「転落」、「道迷い」について適合率、再現率ともに60%以上を達成しました。さらに、SHAP分析(*2)により各カテゴリーの予測に寄与する主要なトークン(*3)を抽出した結果、時間帯・気象条件・山岳情報・人口統計情報が複合的に寄与していたことが判明しました。具体的には、「朝」や「穂高」は滑落リスクと強く関係しており、「昼」や「八ヶ岳」は転倒リスクと関係していました。また、「高齢登山者」の「午後」の活動は疲労リスクと結びついており、「雪」や「霧」といった視界不良の気象条件、そして「単独」は道迷いリスクとの関係が見られました。
本研究成果のさらなる発展により、登山の計画段階で事故リスクを把握し、具体的な準備や判断ができるようになることが期待されます。また本研究は、より多くの人々が安心して自然を楽しめる社会の実現とアウトドア文化のさらなる発展に寄与し、AIを活用したリスク判断や意思決定支援の応用にもつながる可能性があります。
本研究成果は、2025年6月16日に国際学術誌「International Journal of Data Science and Analysis」にオンライン掲載されました。
研究の背景
日本では、登山における遭難が大きな社会的課題となっています。2023年には年間で3126件の山岳遭難が報告され、1961年の統計開始以降、最多となりました。特に長野県は、登山者に人気のある山が多い一方で、地形の険しさから、遭難事故が多く発生している地域の一つです。この課題を解決するためには、登山の計画段階で遭難事故リスクを予測し、対策を施すことが重要です。
従来、遭難事故リスクの予測研究は、統計的手法や調査が主流でした。しかし、計画段階での情報を活用して、リスク予測を行う手法に関しては、これまで十分に検討されていませんでした。そこで本研究グループは、特に遭難件数の多い長野県の過去10年間の山岳事故データを活用し、AI技術を活用した遭難事故リスク予測手法の開発に取り組みました。登山計画段階で得られる情報(登山日、登山ルート、気象条件、人数、登山者の年代など)をテキスト化したうえで、深層学習による言語モデル(BERT)に入力し、それらの文脈情報をもとに「滑落」、「転倒」、「疲労」、「道迷い」の4つの主要な事故リスクを予測する手法を検討しました。そして、従来の統計的手法では困難だった登山前の個別リスク評価を可能にし、登山者一人ひとりが自身の条件に応じた具体的な対策を講じることができる手法の構築を目指しました。
研究結果の詳細
1. 使用したデータセットと機械学習モデルの選定
本研究では、長野県警察のホームページ上で公開されている山岳遭難発生状況のデータセットを使用しました。このデータセットには、2014年1月1日から2023年12月31日までの10年間に長野県の主要な山岳地帯で発生した山岳事故2596件が含まれています。事故の内容としては、滑落が34.1%(884件)を占め、次いで転倒(23.6%、613件)、疲れ(22.3%、579件)、道迷い(20.0%、520件)となっていました。
時期、気象条件、山岳特性、人口統計情報を利用し、「滑落」、「転倒」、「疲れ」、「道迷い」の4つの主要な事故リスクを予測する複数の学習モデルを比較した結果、BERTが最も優れた性能を示し、正解率0.57±0.02、適合率0.57±0.02、再現率0.57±0.02を達成しました。特に「転落」、「道迷い」については、適合率、再現率ともに60%以上を達成しました。
2. SHAP分析による主要なトークンの抽出
SHAP分析により、BERTモデルが各事故リスクを予測する際に重視する特徴を明らかにしました。滑落では、「上級」「穂高」などがプラスの寄与を示し、経験豊富な登山者が困難な地形に挑戦することでリスクが高まることがわかりました。転倒では、「朝」「正午」「女性」「40-60代」が重要で、中高年女性の日中の転倒リスクが高いことが示唆されました。疲労では、「午後5時」「午後10時」「夜」などの時間的特徴が強く、午後遅くから夕方にかけての疲労発生頻度の高さが関係していることが明らかとなりました。道迷いでは、「夕方」「夜」「霧」「雪」が重要で、視界制限や認知機能低下による道迷いリスクを反映していることがわかりました。
本研究を主導した佐藤 多恵子氏と深澤准教授は、「本研究は、自然言語処理の演習でBERTを活用した際に、登山に関するテキストデータでの遭難リスク予測の可能性に気づいたこと、高尾山での登山体験で遭難事故の多さを実感したことから始まりました。本研究成果は、近年広く普及している登山のサポートアプリやWEBサービスに応用することで、安全性向上に寄与できると考えています。さらに、本研究手法は登山だけでなく、日常生活や他分野におけるリスク判断や意思決定支援への応用も期待されます。そうした意味で、AI技術を通じて社会課題の解決に取り組む幅広い層の方々にも、本研究の成果が届くことを願っています」と、研究成果についてコメントしています。
用語
*1: BERT
Googleが開発した自然言語処理モデル。Transformerと呼ばれるニューラルネットワークを基にしており、単語の意味を前後の文脈から判断することができる。
*2: SHAP(SHapley Additive exPlanation)
予測値に対して各特徴量がどの程度寄与しているかを評価する手法。
*3: トークン
AIが文章を理解するために文字列を分割した最小単位で、単語や文字の組み合わせを指す。
論文名および著者
- 媒体名
International Journal of Data Science and Analytics
- 論文名
From planning to prevention: predicting mountain accident risks using pre-climb information
- オンライン版URL
- 著者(共著)
Taeko Sato and Yusuke Fukazawa
研究内容に関するお問合せ
上智大学大学院 応用データサイエンス学位プログラム
准教授 深澤 佑介 fukazawa@sophia.ac.jp
報道関係のお問合せ
上智学院広報グループ
sophiapr-co@sophia.ac.jp